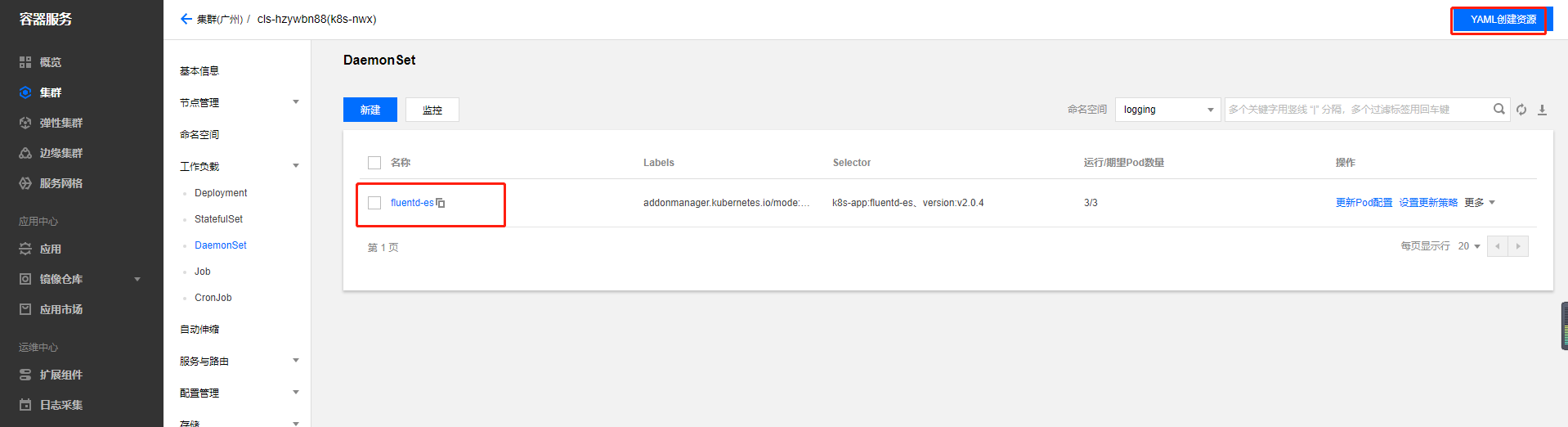
本篇文章介绍了如何在TKE集群中搭建EFK日志采集系统来采集集群日志。
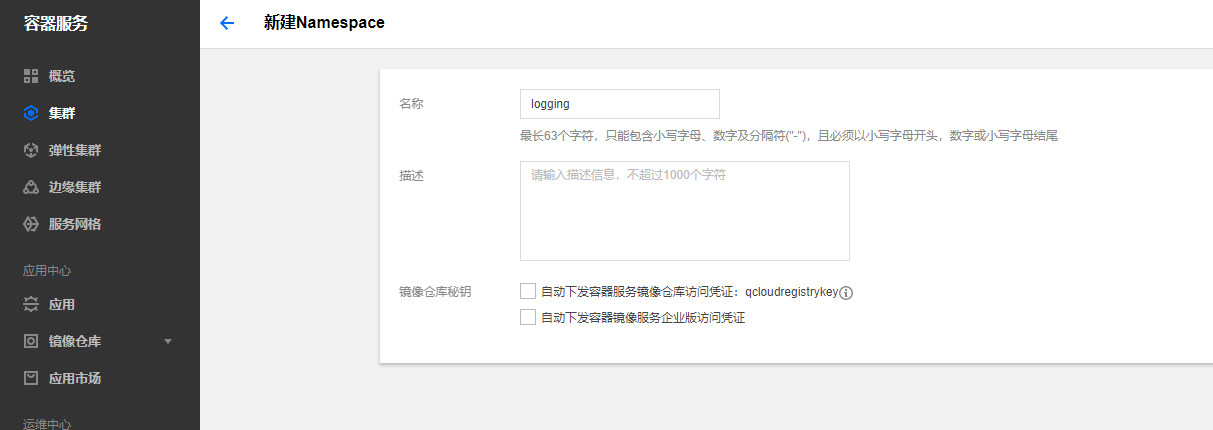
创建新的namespace
创建一个新的namespace为logging,该命名空间来部署EFK
创建ES的svc
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| kind: Service
apiVersion: v1
metadata:
name: elasticsearch
namespace: logging
labels:
app: elasticsearch
spec:
selector:
app: elasticsearch
clusterIP: None
ports:
- port: 9200
name: rest
- port: 9300
name: inter-node
|

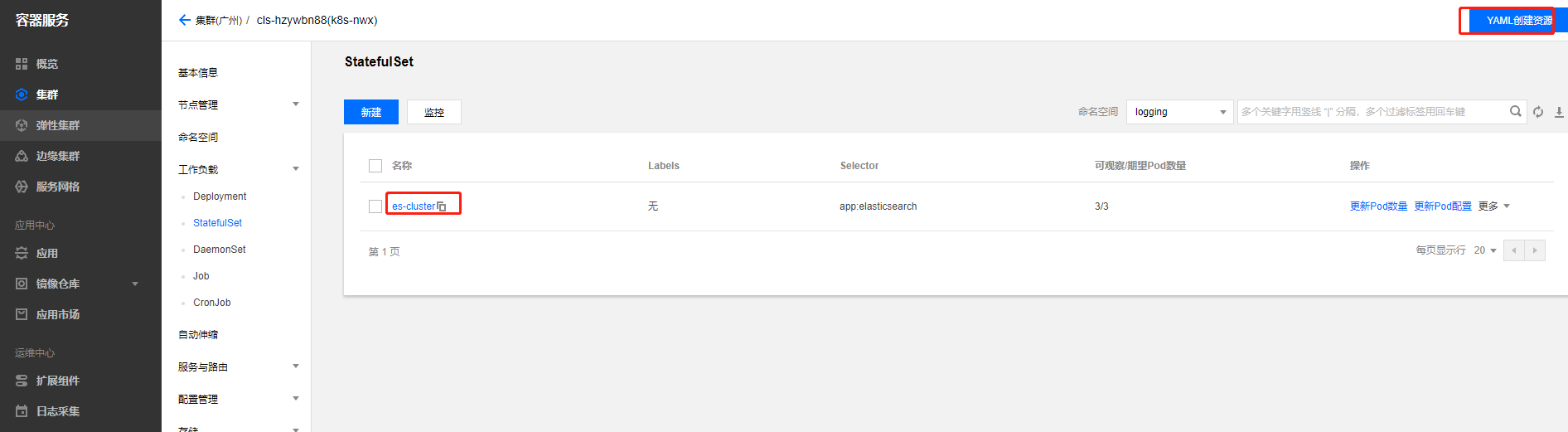
创建ES的StatefulSet资源
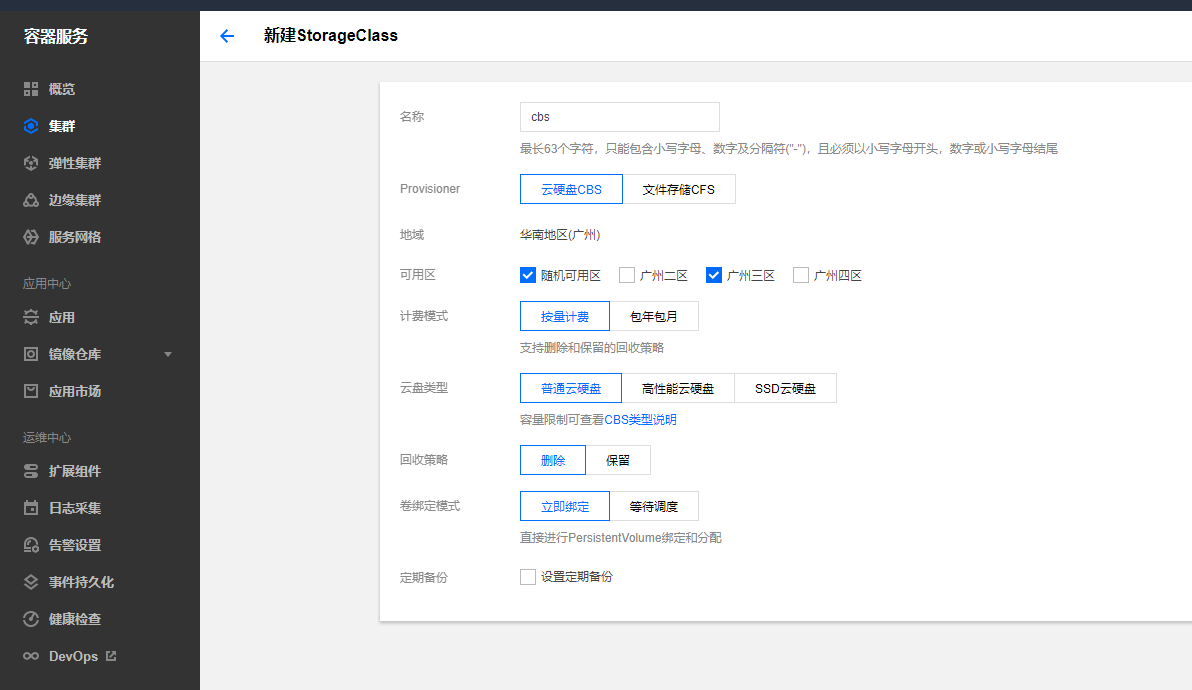
创建StorageClass
需要创建一个SC,用来后续ES创建时候动态挂载PVC,在腾讯云中,如果挂载了卷,又起了多个pod,可以采用自动动态挂载PVC
1
2
3
4
5
6
7
8
9
10
11
| volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: es-data-db
resources:
requests:
storage: 50Gi
|
在资源中通过volumeClaimTemplates自动常见PV来挂载PVC
创建StatefulSet
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
| apiVersion: apps/v1
kind: StatefulSet
metadata:
name: es-cluster
namespace: logging
spec:
serviceName: elasticsearch
replicas: 3
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: elasticsearch:6.4.3
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: rest
protocol: TCP
- containerPort: 9300
name: inter-node
protocol: TCP
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: cluster.name
value: k8s-logs
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: discovery.zen.ping.unicast.hosts
value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch"
- name: discovery.zen.minimum_master_nodes
value: "2"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
initContainers:
- name: fix-permissions
image: busybox
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: cbs
resources:
requests:
storage: 10Gi
|
创建kibana服务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: logging
labels:
app: kibana
spec:
ports:
- port: 5601
type: NodePort
selector:
app: kibana
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: logging
labels:
app: kibana
spec:
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana-oss:6.4.3
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_URL
value: http://elasticsearch:9200
ports:
- containerPort: 5601
|

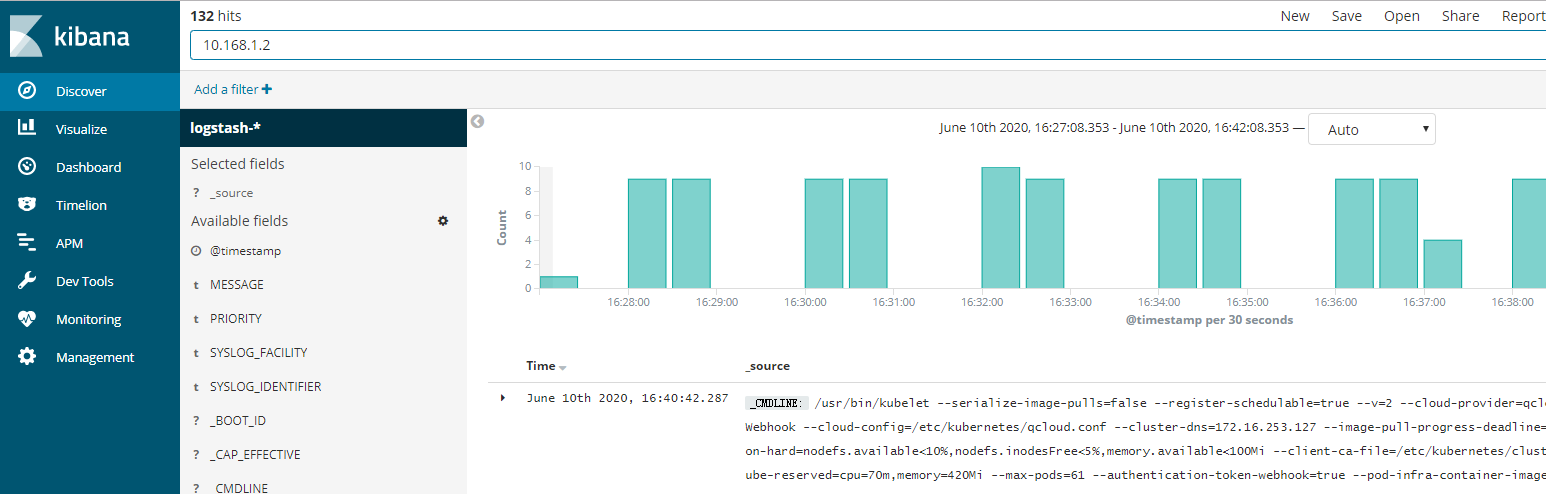
通过http://任意节点ip:31020访问kibana界面
部署Fluentd
添加fluentd的配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
| kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-config
namespace: logging
labels:
addonmanager.kubernetes.io/mode: Reconcile
data:
system.conf: |-
<system>
root_dir /tmp/fluentd-buffers/
</system>
containers.input.conf: |-
<source>
@id fluentd-containers.log
@type tail
path /var/log/containers/*.log
pos_file /var/log/es-containers.log.pos
time_format %Y-%m-%dT%H:%M:%S.%NZ
localtime
tag raw.kubernetes.*
format json
read_from_head true
</source>
<match raw.kubernetes.**>
@id raw.kubernetes
@type detect_exceptions
remove_tag_prefix raw
message log
stream stream
multiline_flush_interval 5
max_bytes 500000
max_lines 1000
</match>
system.input.conf: |-
<source>
@id journald-docker
@type systemd
filters [{ "_SYSTEMD_UNIT": "docker.service" }]
<storage>
@type local
persistent true
</storage>
read_from_head true
tag docker
</source>
<source>
@id journald-kubelet
@type systemd
filters [{ "_SYSTEMD_UNIT": "kubelet.service" }]
<storage>
@type local
persistent true
</storage>
read_from_head true
tag kubelet
</source>
forward.input.conf: |-
<source>
@type forward
</source>
output.conf: |-
<filter kubernetes.**>
@type kubernetes_metadata
</filter>
<match **>
@id elasticsearch
@type elasticsearch
@log_level info
include_tag_key true
host elasticsearch
port 9200
logstash_format true
request_timeout 30s
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever
retry_max_interval 30
chunk_limit_size 2M
queue_limit_length 8
overflow_action block
</buffer>
</match>
|
部署fluentd
fluentdt需要收集所有节点的日志,所以通过deamonset的方式部署
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
| apiVersion: apps/v1beta2
kind: DaemonSet
metadata:
name: fluentd-es
namespace: logging
labels:
k8s-app: fluentd-es
version: v2.0.4
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
selector:
matchLabels:
k8s-app: fluentd-es
version: v2.0.4
template:
metadata:
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
version: v2.0.4
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
serviceAccountName: fluentd-es
containers:
- name: fluentd-es
image: cnych/fluentd-elasticsearch:v2.0.4
env:
- name: FLUENTD_ARGS
value: --no-supervisor -q
resources:
limits:
memory: 500Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /data/docker/containers
readOnly: true
- name: config-volume
mountPath: /etc/fluent/config.d
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /data/docker/containers
- name: config-volume
configMap:
name: fluentd-config
|