该文章介绍了如何在k8s集群中搭建prometheus来监控集群并通过AlertManager发送告警。
新建namespace部署prometheus
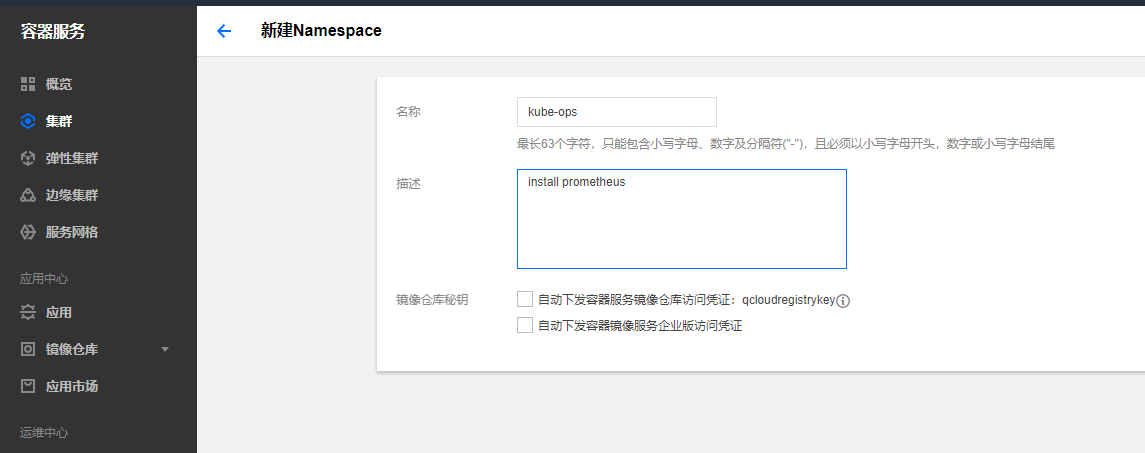
部署prometheus
创建pvc挂载卷挂载prometheus数据
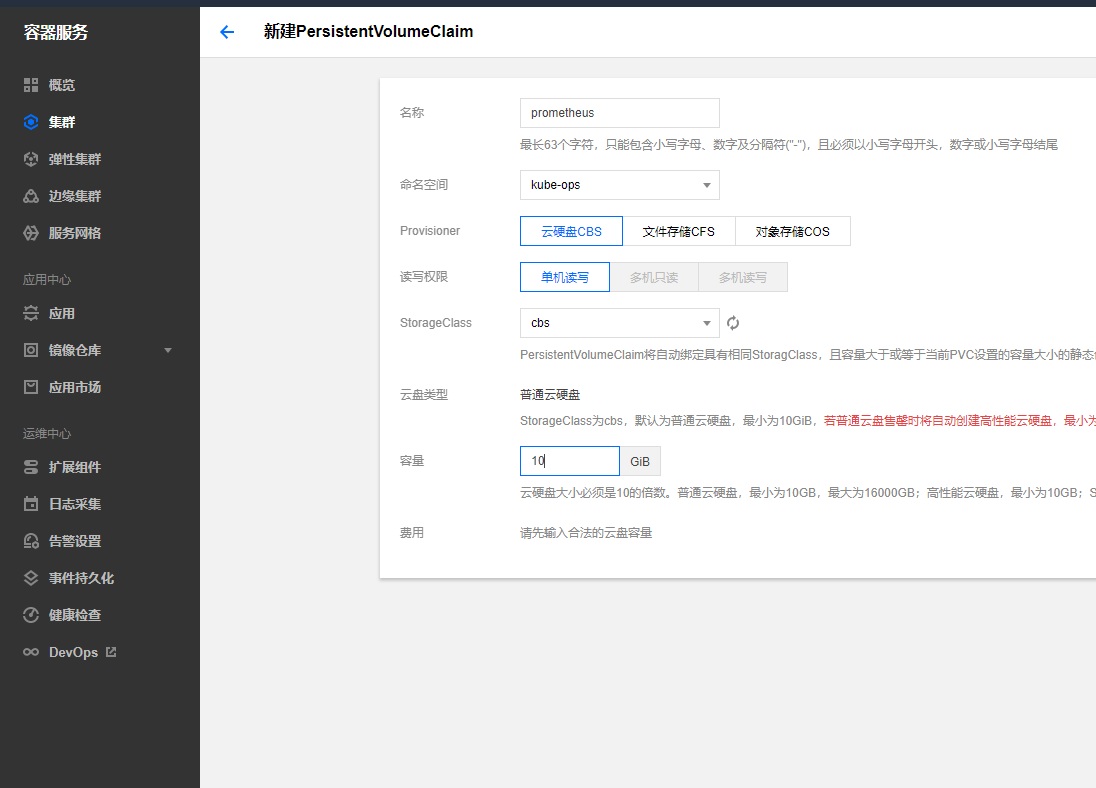
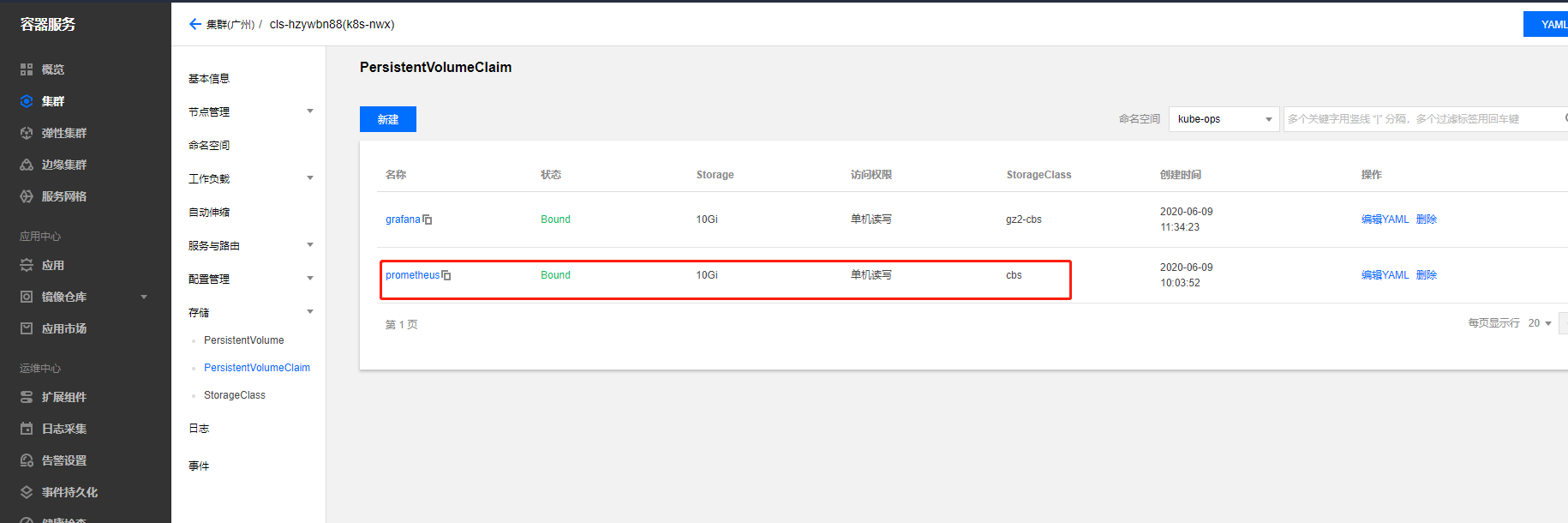
通过configmap配置prometheus配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-ops
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
|
创建prometheus的pod资源

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: prometheus
namespace: kube-ops
labels:
app: prometheus
spec:
template:
metadata:
labels:
app: prometheus
spec:
serviceAccountName: prometheus
containers:
- image: prom/prometheus:v2.4.3
name: prometheus
command:
- "/bin/prometheus"
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus"
- "--storage.tsdb.retention=24h"
- "--web.enable-admin-api" # 控制对admin HTTP API的访问,其中包括删除时间序列等功能
- "--web.enable-lifecycle" # 支持热更新,直接执行localhost:9090/-/reload立即生效
ports:
- containerPort: 9090
protocol: TCP
name: http
volumeMounts:
- mountPath: "/prometheus"
subPath: prometheus
name: data
- mountPath: "/etc/prometheus"
name: config-volume
resources:
requests:
cpu: 100m
memory: 512Mi
limits:
cpu: 100m
memory: 512Mi
securityContext:
runAsUser: 0
volumes:
- name: data
persistentVolumeClaim:
claimName: prometheus
- configMap:
name: prometheus-config
name: config-volume
|
创建prometheus的svc

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: kube-ops
labels:
app: prometheus
spec:
selector:
app: prometheus
type: NodePort
ports:
- name: web
port: 9090
targetPort: http
|
页面访问prometheus

我们就可以通过http://任意节点IP:31160访问 prometheus 的 webui 服务了。
监控集群节点
可以通过node_exporter来获取,顾名思义,node_exporter 就是抓取用于采集服务器节点的各种运行指标,目前 node_exporter 支持几乎所有常见的监控点,比如 conntrack,cpu,diskstats,filesystem,loadavg,meminfo,netstat等

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: node-exporter
namespace: kube-ops
labels:
name: node-exporter
spec:
template:
metadata:
labels:
name: node-exporter
spec:
hostPID: true
hostIPC: true
hostNetwork: true
containers:
- name: node-exporter
image: prom/node-exporter:v0.16.0
ports:
- containerPort: 9100
resources:
requests:
cpu: 0.15
securityContext:
privileged: true
args:
- --path.procfs
- /host/proc
- --path.sysfs
- /host/sys
- --collector.filesystem.ignored-mount-points
- '"^/(sys|proc|dev|host|etc)($|/)"'
volumeMounts:
- name: dev
mountPath: /host/dev
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: rootfs
mountPath: /rootfs
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
volumes:
- name: proc
hostPath:
path: /proc
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: rootfs
hostPath:
path: /
|
我们上面是指定了hostNetwork=true,所以在每个节点上就会绑定一个端口 9100,我们可以通过这个端口去获取到监控指标数据,不需要创建service
让 Prometheus 也能够获取到当前集群中的所有节点信息的话,我们就需要利用 Node 的服务发现模式,同样的prometheus.yml 文件中配置如下的 job 任务即可
prometheus 去发现 Node 模式的服务的时候,访问的端口默认是10250,而现在该端口下面已经没有了/metrics指标数据了,现在 kubelet 只读的数据接口统一通过10255端口进行暴露了,所以我们应该去替换掉这里的端口,但是我们是要替换成10255端口吗?不是的,因为我们是要去配置上面通过node-exporter抓取到的节点指标数据,而我们上面是不是指定了hostNetwork=true,所以在每个节点上就会绑定一个端口9100,所以我们应该将这里的10250替换成9100,但是应该怎样替换呢?
这里我们就需要使用到 Prometheus 提供的relabel_configs中的replace能力了,relabel 可以在 Prometheus 采集数据之前,通过Target 实例的 Metadata 信息,动态重新写入 Label 的值。除此之外,我们还能根据 Target 实例的 Metadata 信息选择是否采集或者忽略该 Target 实例。比如我们这里就可以去匹配__address__这个 Label 标签,然后替换掉其中的端口
最终添加如下job即可
1
2
3
4
5
6
7
8
9
| - job_name: 'kubernetes-nodes'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
|
由于 kubelet 也自带了一些监控指标数据,就上面我们提到的10255端口,所以我们这里也把 kubelet 的监控任务也一并配置上
1
2
3
4
5
6
7
8
9
10
11
| - job_name: 'kubernetes-kubelet'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
|

curl一下接口,使配置项生效,去prometheus 的 dashboard 中查看 Targets 是否能够正常抓取数据
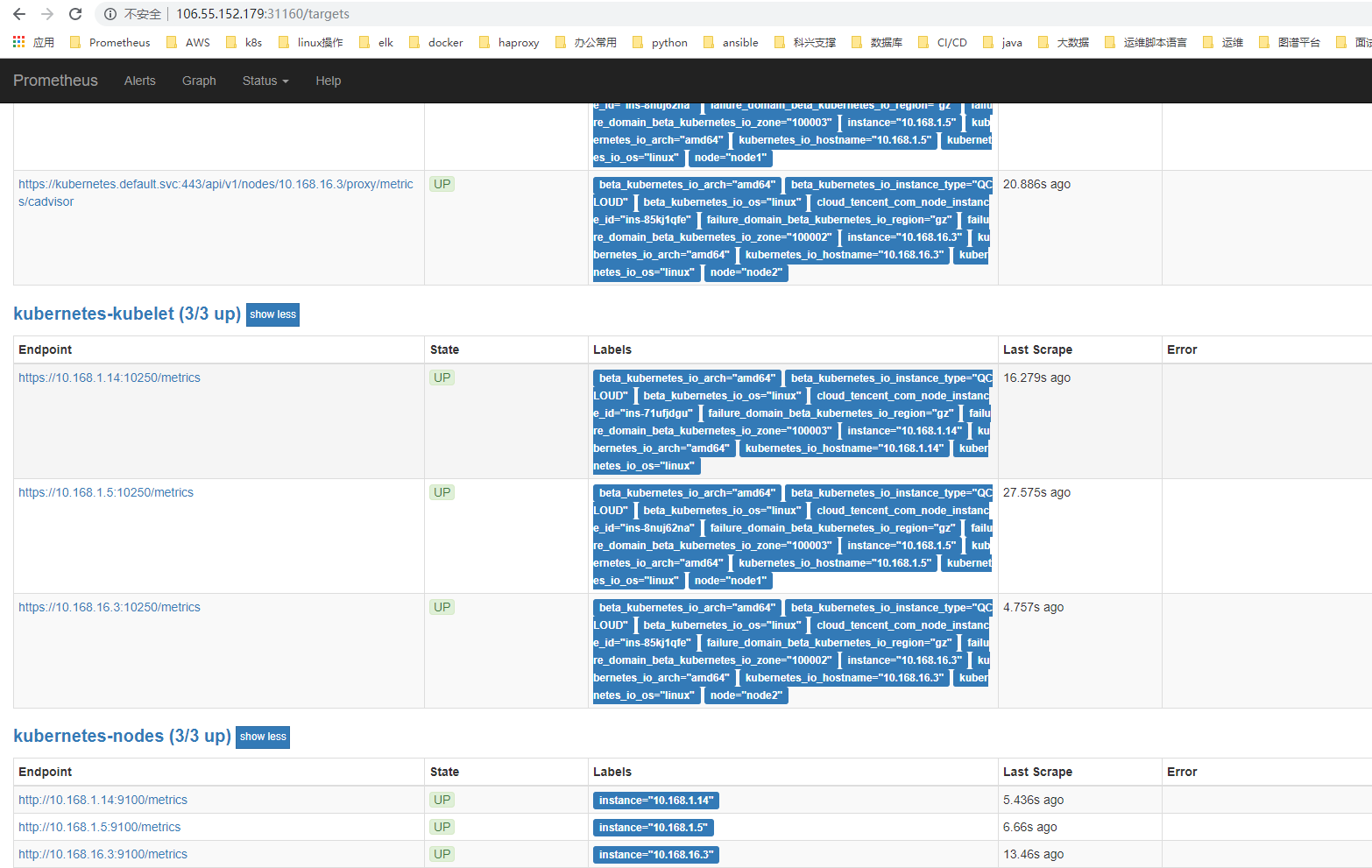
容器监控
容器监控我们自然会想到cAdvisor,我们前面也说过cAdvisor已经内置在了 kubelet 组件之中,所以我们不需要单独去安装,cAdvisor的数据路径为/api/v1/nodes//proxy/metrics,同样我们这里使用 node 的服务发现模式,因为每一个节点下面都有 kubelet,自然都有cAdvisor采集到的数据指标,在prometheus.yaml中配置一下即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| - job_name: 'kubernetes-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
|

reload使配置生效
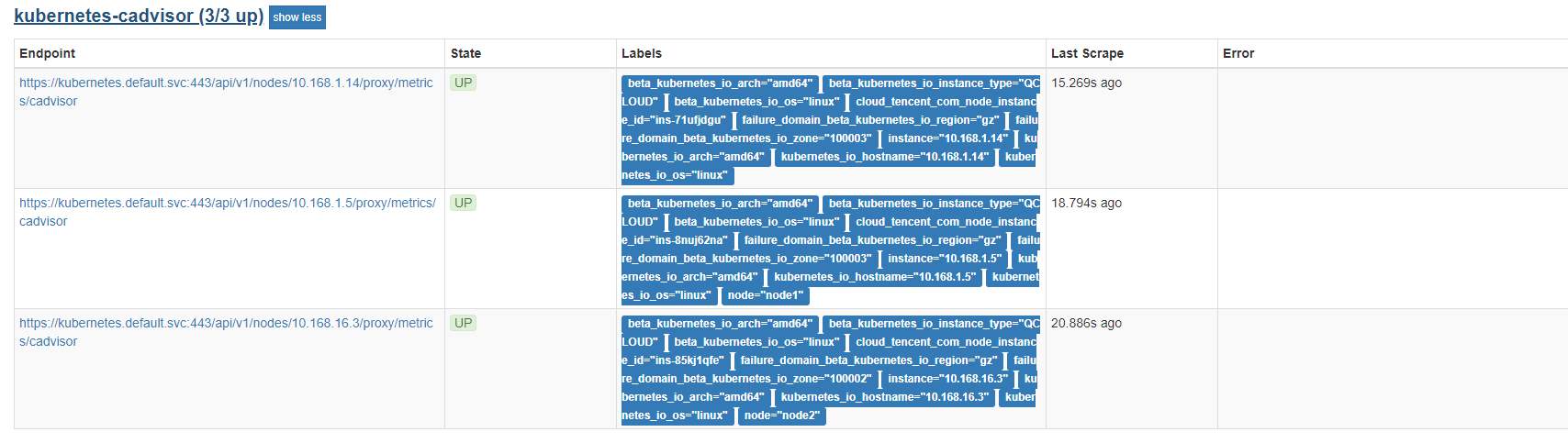
界面查看cadvisor的target是否生效
Apiservice的监控
集群的 apiserver 在集群内部的 Service 地址,要自动发现 Service 类型的服务,我们就需要用到 role 为 Endpoints 的 kubernetes_sd_configs,我们可以在 ConfigMap 对象中添加上一个 Endpoints 类型的服务的监控任务
由于 kubernetes 这个服务对应的端口是443,需要使用 https 协议,所以这里我们需要使用 https 的协议,对应的就需要将对应的 ca 证书配置上,最终配置如下
1
2
3
4
5
6
7
8
9
10
11
| - job_name: 'kubernetes-apiservers'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
|

reload使prometheus.yml配置生效

Service的监控
配置一个任务用来专门发现普通类型的 Service
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| - job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
|
想自动发现集群中的 Service,就需要我们在 Service 的annotation区域添加prometheus.io/scrape=true的声明
我们修改下redis的service,生效后可以在target中查看到
1
2
3
4
| metadata:
annotations:
prometheus.io/port: "9121"
prometheus.io/scrape: "true"
|

部署kube-state-metrics
kube-state-metrice主要是负责监控pod、DaemonSet、Deployment、Job、CronJob 等各种资源对象的状态
部署kube-state-metrice的pod应用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
| apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-state-metrics
namespace: kube-ops
labels:
k8s-app: kube-state-metrics
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
version: v1.3.0
spec:
selector:
matchLabels:
k8s-app: kube-state-metrics
version: v1.3.0
replicas: 1
template:
metadata:
labels:
k8s-app: kube-state-metrics
version: v1.3.0
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
priorityClassName: system-cluster-critical
serviceAccountName: kube-state-metrics
containers:
- name: kube-state-metrics
image: zhaocheng172/kube-state-metrics:v1.3.0
ports:
- name: http-metrics
containerPort: 8080
- name: telemetry
containerPort: 8081
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
timeoutSeconds: 5
- name: addon-resizer
image: zhaocheng172/addon-resizer:1.8.3
resources:
limits:
cpu: 100m
memory: 30Mi
requests:
cpu: 100m
memory: 30Mi
env:
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumeMounts:
- name: config-volume
mountPath: /etc/config
command:
- /pod_nanny
- --config-dir=/etc/config
- --container=kube-state-metrics
- --cpu=100m
- --extra-cpu=1m
- --memory=100Mi
- --extra-memory=2Mi
- --threshold=5
- --deployment=kube-state-metrics
volumes:
- name: config-volume
configMap:
name: kube-state-metrics-config
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kube-state-metrics-config
namespace: kube-ops
labels:
k8s-app: kube-state-metrics
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
data:
NannyConfiguration: |-
apiVersion: nannyconfig/v1alpha1
kind: NannyConfiguration
|
部署kube-state-metrice的service
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| apiVersion: v1
kind: Service
metadata:
name: kube-state-metrics
namespace: kube-ops
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "kube-state-metrics"
annotations:
prometheus.io/scrape: 'true'
spec:
ports:
- name: http-metrics
port: 8080
targetPort: http-metrics
protocol: TCP
- name: telemetry
port: 8081
targetPort: telemetry
protocol: TCP
selector:
k8s-app: kube-state-metrics
|
kube-state-metrics-service.yaml 对 Service 的定义包含prometheus.io/scrape: ‘true’这样的一个annotation,因此 kube-state-metrics 的 endpoint 可以被 Prometheus 自动服务发现

部署granafa
新建pvc做数据持久化
创建grafana的svc
1
2
3
4
5
6
7
8
9
10
11
12
13
| apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: kube-ops
labels:
app: grafana
spec:
type: NodePort
ports:
- port: 3000
selector:
app: grafana
|
创建gafana的deployment
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: grafana
namespace: kube-ops
labels:
app: grafana
spec:
revisionHistoryLimit: 10
template:
metadata:
labels:
app: grafana
spec:
containers:
- name: grafana
image: grafana/grafana:5.3.4
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3000
name: grafana
env:
- name: GF_SECURITY_ADMIN_USER
value: admin
- name: GF_SECURITY_ADMIN_PASSWORD
value: admin321
readinessProbe:
failureThreshold: 10
httpGet:
path: /api/health
port: 3000
scheme: HTTP
initialDelaySeconds: 60
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 30
livenessProbe:
failureThreshold: 3
httpGet:
path: /api/health
port: 3000
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
resources:
limits:
cpu: 100m
memory: 256Mi
requests:
cpu: 100m
memory: 256Mi
volumeMounts:
- mountPath: /var/lib/grafana
subPath: grafana
name: storage
securityContext:
fsGroup: 472
runAsUser: 472
volumes:
- name: storage
persistentVolumeClaim:
claimName: grafana
|
访问grafana界面

现在我们就可以在浏览器中使用http://<任意节点IP:31838>来访问 grafana 这个服务了:

登录账号密码从deployment的配置文件查看
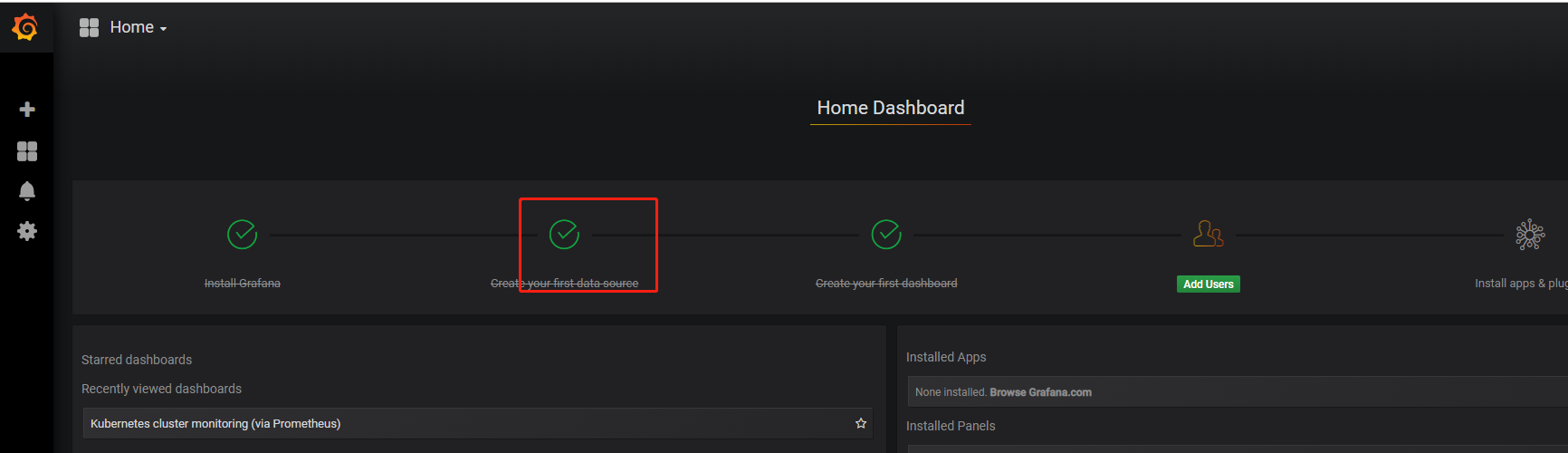
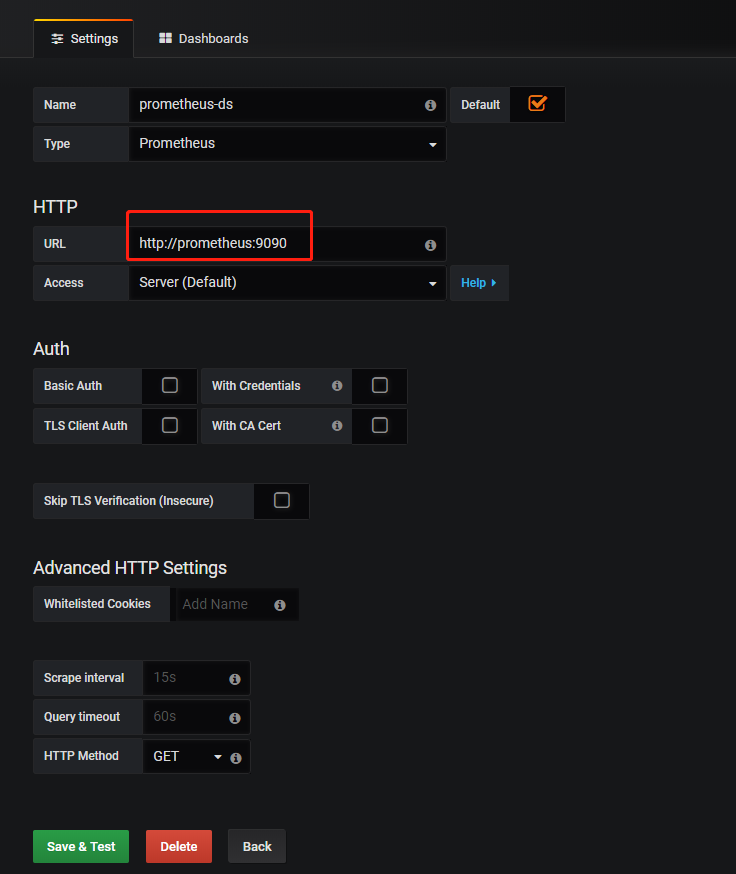
配置数据源
添加Dashboard
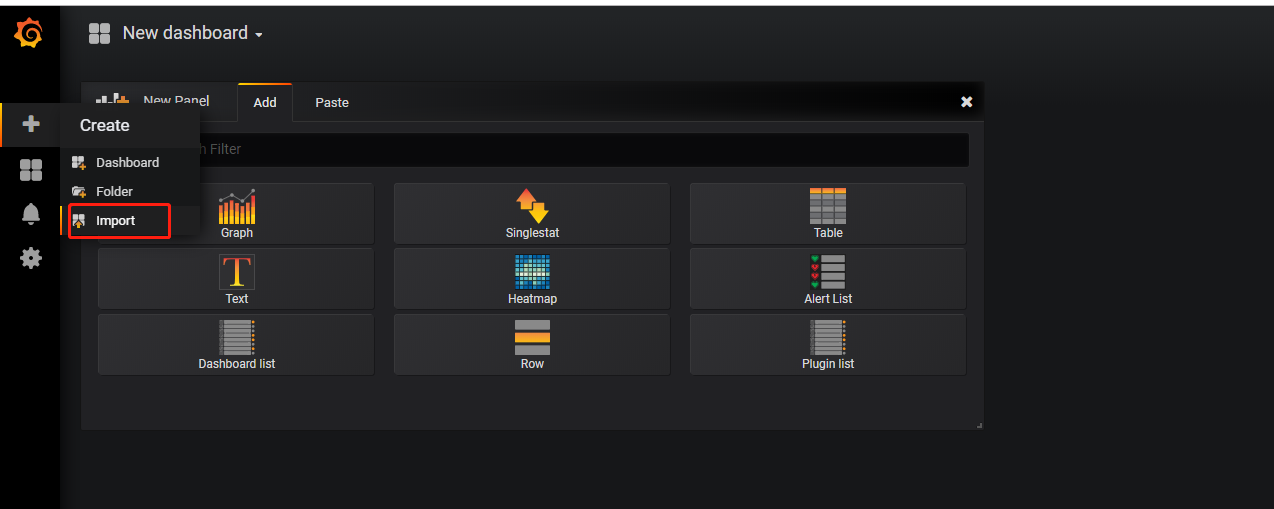
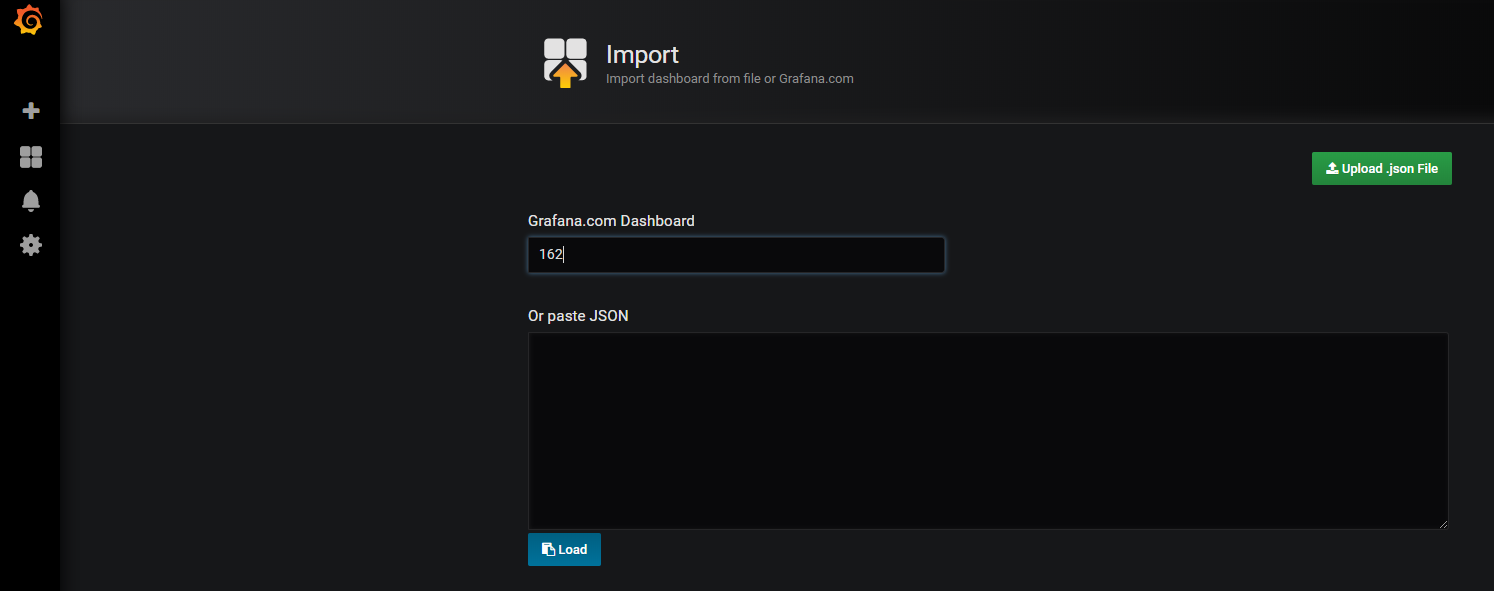
我们这里可以使用Kubernetes cluster monitoring (via Prometheus)(dashboard id 为162)
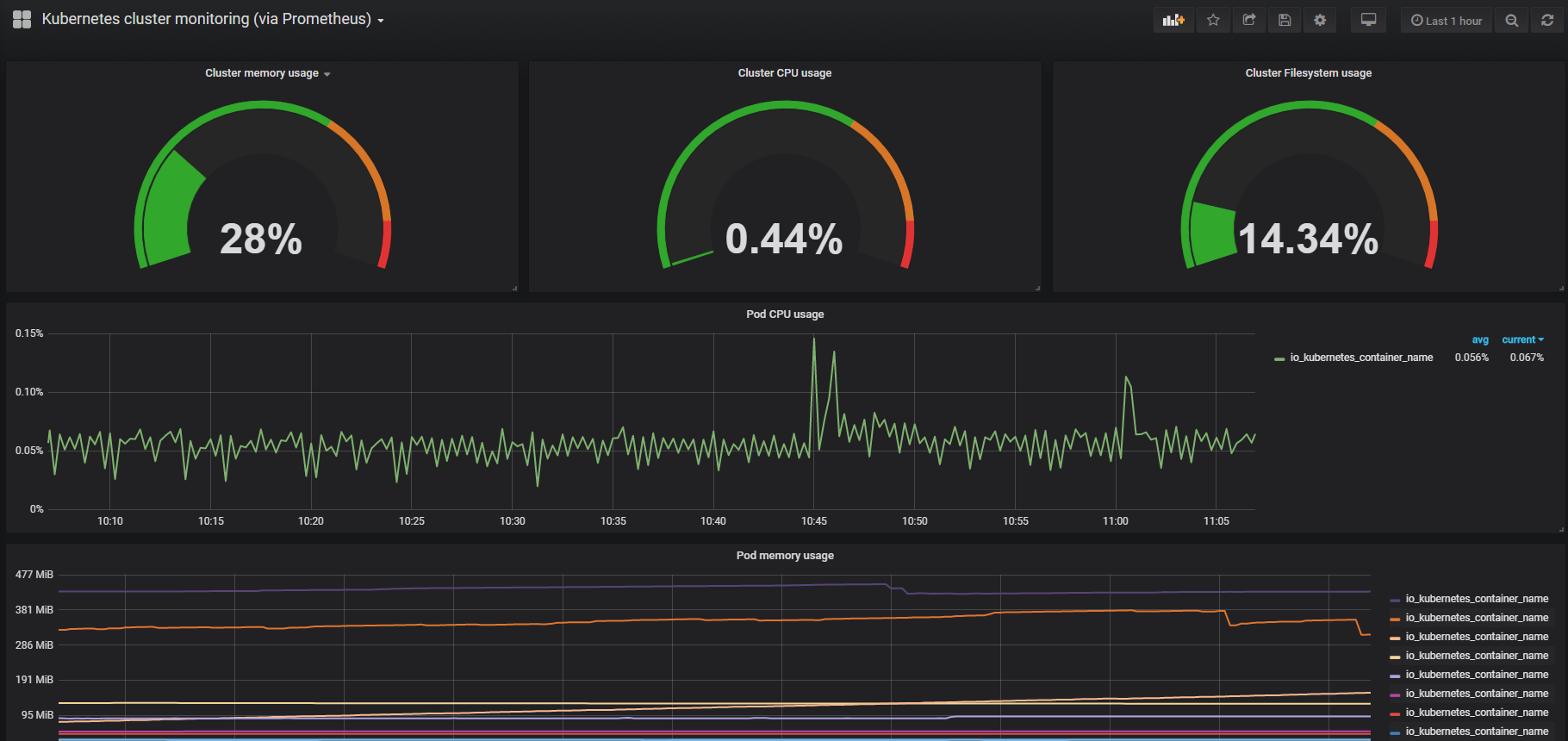
AlertManager配置告警
配置告警配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager
namespace: monitor
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: EnsureExists
data:
config.yml: |
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: 'nwx*****@163.com'
smtp_auth_username: 'nwx****@163.com'
smtp_auth_password: '*******'
smtp_require_tls: false
templates:
- '/etc/alertmanager-templates/*.tmpl'
route:
group_by: ['alertname']
group_interval: 1m
group_wait: 10s
receiver: default-receiver
repeat_interval: 1m
receivers:
- name: default-receiver
email_configs:
- to: "niewx****@163.com"
html: '{ template "emai.html" . }' # 模板
headers: { Subject: " { .CommonLabels.instance } { CommonAnnotations.summary }" } #标题
|
配置告警发送模板文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
| apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager-templates
namespace: monitor
data:
default.tmpl: |
{ define "emai.html" }
{ range .Alerts }
<pre>
实例: { .Labels.instance }
信息: { .Annotations.summary }
详情: { .Annotations.description }
时间: { .StartsAt.Format "2006-01-02 15:04:05" }
</pre>
{ end }
{ end }
{ define "__alertmanager" }AlertManager{ end }
{ define "__subject" }[{ .Status | toUpper }{ if eq .Status "firing" }:{ .Alerts.Firing | len }{ end }] { .GroupLabels.SortedPairs.Values | join " " } { if gt (len .CommonLabels) (len .GroupLabels) }({ with .CommonLabels.Remove .GroupLabels.Names }{ .Values | join " " }{ end }){ end }{ end }
{ define "__single_message_title" }{ range .Alerts.Firing }{ .Labels.alertname } @ { .Annotations.identifier }{ end }{ range .Alerts.Resolved }{ .Labels.alertname } @ { .Annotations.identifier }{ end }{ end }
{ define "custom_title" }[{ .Status | toUpper }{ if eq .Status "firing" }:{ .Alerts.Firing | len }{ end }] { if or (and (eq (len .Alerts.Firing) 1) (eq (len .Alerts.Resolved) 0)) (and (eq (len .Alerts.Firing) 0) (eq (len .Alerts.Resolved) 1)) }{ template "__single_message_title" . }{ end }{ end }
{ define "custom_slack_message" }
{ if or (and (eq (len .Alerts.Firing) 1) (eq (len .Alerts.Resolved) 0)) (and (eq (len .Alerts.Firing) 0) (eq (len .Alerts.Resolved) 1)) }
{ range .Alerts.Firing }
*报警类型: * { .Labels.service }
*报警描述: * { .Annotations.description }
{ end }
{ range .Alerts.Resolved }
*报警恢复: * { .Annotations.resolved }{ end }
{ else }
{ if gt (len .Alerts.Firing) 0 }
{ range .Alerts.Firing }
*报警类型: * { .Labels.service }
*报警描述: * { .Annotations.description }
{ end }{ end }
{ if gt (len .Alerts.Resolved) 0 }
{ range .Alerts.Resolved }
*报警类型: * { .Labels.service }
*报警恢复: * { .Annotations.resolved }
{ end }{ end }
{ end }
{ end }
{ define "slack.default.title" }{ template "__subject" . }{ end }
{ define "slack.default.username" }{ template "__alertmanager" . }{ end }
{ define "slack.default.fallback" }{ template "slack.default.title" . } | { template "slack.default.titlelink" . }{ end }
{ define "slack.default.pretext" }{ end }
{ define "slack.default.titlelink" }{ template "__alertmanagerURL" . }{ end }
{ define "slack.default.iconemoji" }{ end }
{ define "slack.default.iconurl" }{ end }
{ define "slack.default.text" }{ end }
{ define "slack.default.footer" }{ end }
{ define "wechat.html" }
{ range .Alerts }
========start==========
告警程序: prometheus_alert
告警级别: { .Labels.severity }
告警类型: { .Labels.alertname }
故障主机: { .Labels.instance }
告警主题: { .Annotations.summary }
告警详情: { .Annotations.description }
触发时间: { .StartsAt.Format "2019-01-01 01:01:01" }
========end==========
{ end }
{ end }
|
配置alertmanager容器
我们可以直接在之前的 Prometheus 的 Pod 中添加这个容器,对应的 YAML 资源声明如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| containers:
- args:
- --config.file=/etc/alertmanager/config.yml
- --storage.path=/alertmanager/data
image: prom/alertmanager:v0.15.3
imagePullPolicy: IfNotPresent
name: alertmanager
ports:
- containerPort: 9093
name: http
protocol: TCP
resources:
limits:
cpu: 100m
memory: 256Mi
requests:
cpu: 100m
memory: 256Mi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /etc/alertmanager
name: alertcfg
- mountPath: /etc/alertmanager-templates
name: templates-volume
|
prometheus中配置alermanager
Prometheus 中配置下 AlertManager 的地址,让 Prometheus 能够访问到 AlertManager
1
2
3
4
| alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"]
|
设置告警规则
直接在prometheus的配置文件中配置告警规则
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| rules.yml: |2-
groups:
- name: test-rule
rules:
- alert: NodeFilesystemUsage
expr: (node_filesystem_size_bytes{device="rootfs"} - node_filesystem_free_bytes{device="rootfs"}) / node_filesystem_size_bytes{device="rootfs"} * 100 > 20
for: 2m
labels:
team: node
annotations:
summary: "{$labels.instance}: High Filesystem usage detected"
description: "{$labels.instance}: Filesystem usage is above 80% (current value is: { $value }"
- alert: NodeMemoryUsage
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100 > 20
for: 2m
labels:
team: node
annotations:
summary: "{$labels.instance}: High Memory usage detected"
description: "{$labels.instance}: Memory usage is above 80% (current value is: { $value }"
- alert: NodeCPUUsage
expr: (100 - (avg by (instance) (irate(node_cpu{job="kubernetes-node-exporter",mode="idle"}[5m])) * 100)) > 20
for: 2m
labels:
team: node
annotations:
summary: "{$labels.instance}: High CPU usage detected"
description: "{$labels.instance}: CPU usage is above 80% (current value is: { $value }"
|
查看告警
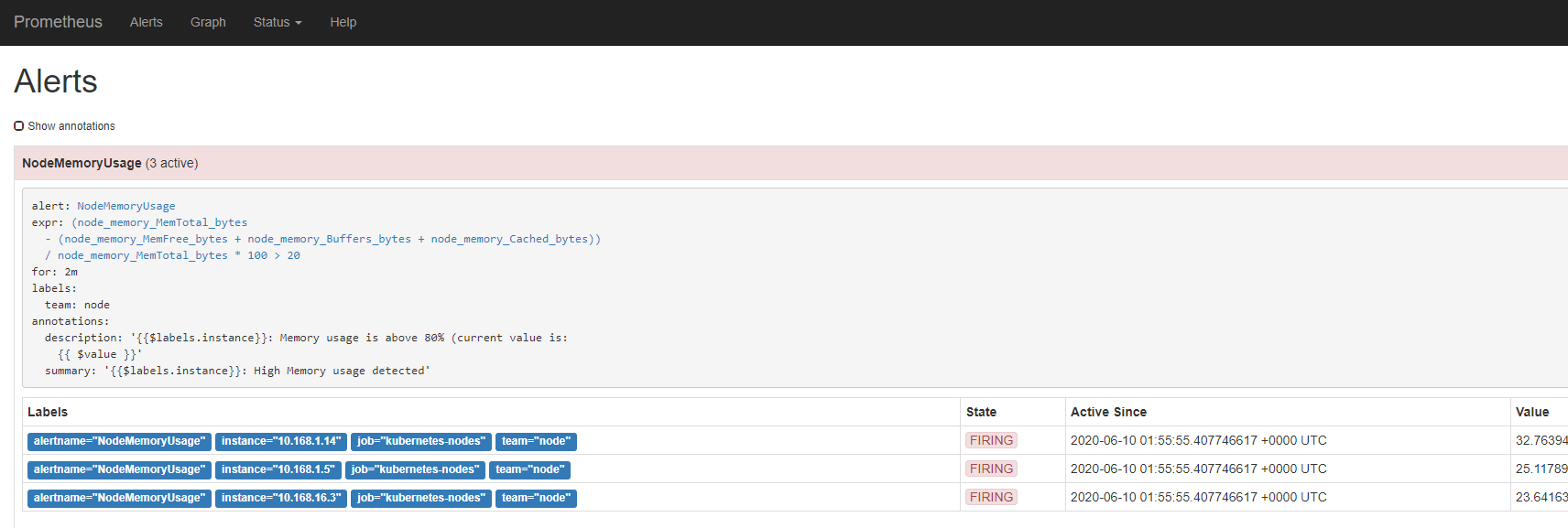
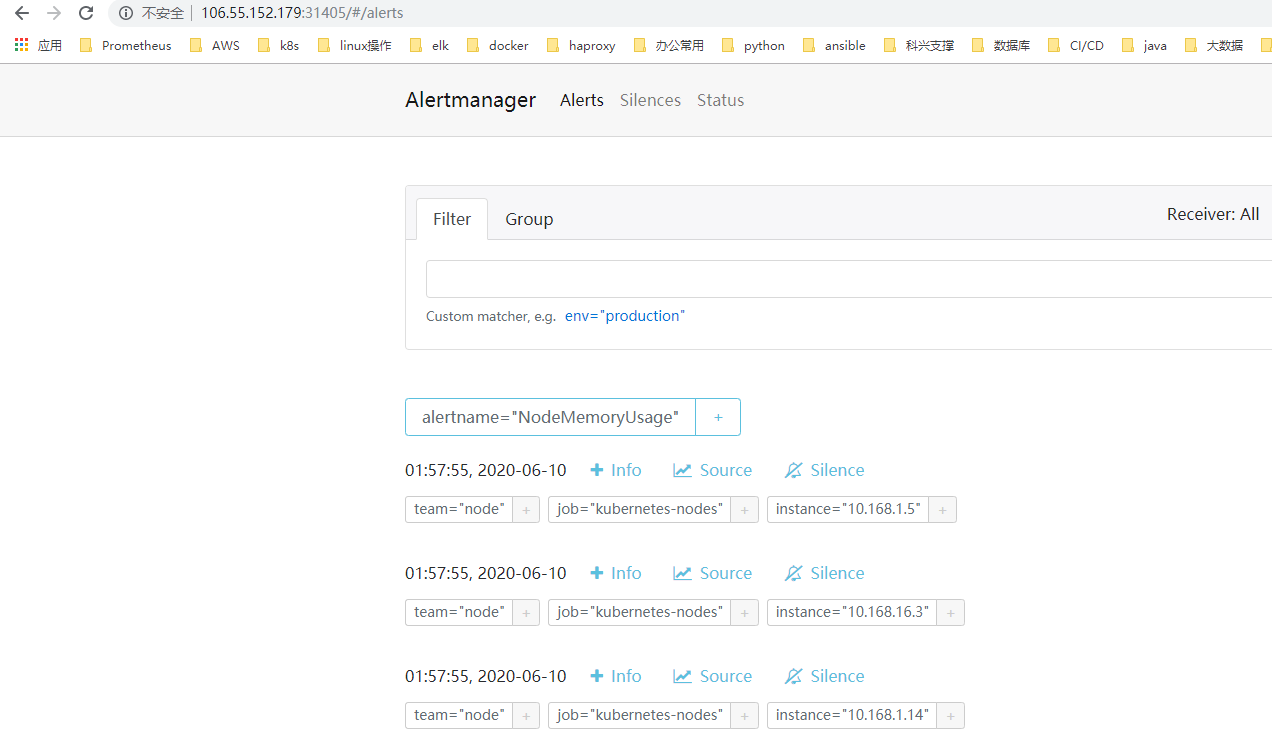
在这个页面中我们可以进行一些操作,比如过滤、分组等等,里面还有两个新的概念:Inhibition(抑制)和 Silences(静默)。
- Inhibition:如果某些其他警报已经触发了,则对于某些警报,Inhibition 是一个抑制通知的概念。例如:一个警报已经触发,它正在通知整个集群是不可达的时,Alertmanager 则可以配置成关心这个集群的其他警报无效。这可以防止与实际问题无关的数百或数千个触发警报的通知,Inhibition 需要通过上面的配置文件进行配置。
- Silences:静默是一个非常简单的方法,可以在给定时间内简单地忽略所有警报。Silences 基于 matchers配置,类似路由树。来到的警告将会被检查,判断它们是否和活跃的 Silences 相等或者正则表达式匹配。如果匹配成功,则不会将这些警报发送给接收者。
由于全局配置中我们配置的repeat_interval: 5m,所以正常来说,上面的测试报警如果一直满足报警条件(CPU使用率大于20%)的话,那么每5分钟我们就可以收到一条报警邮件。
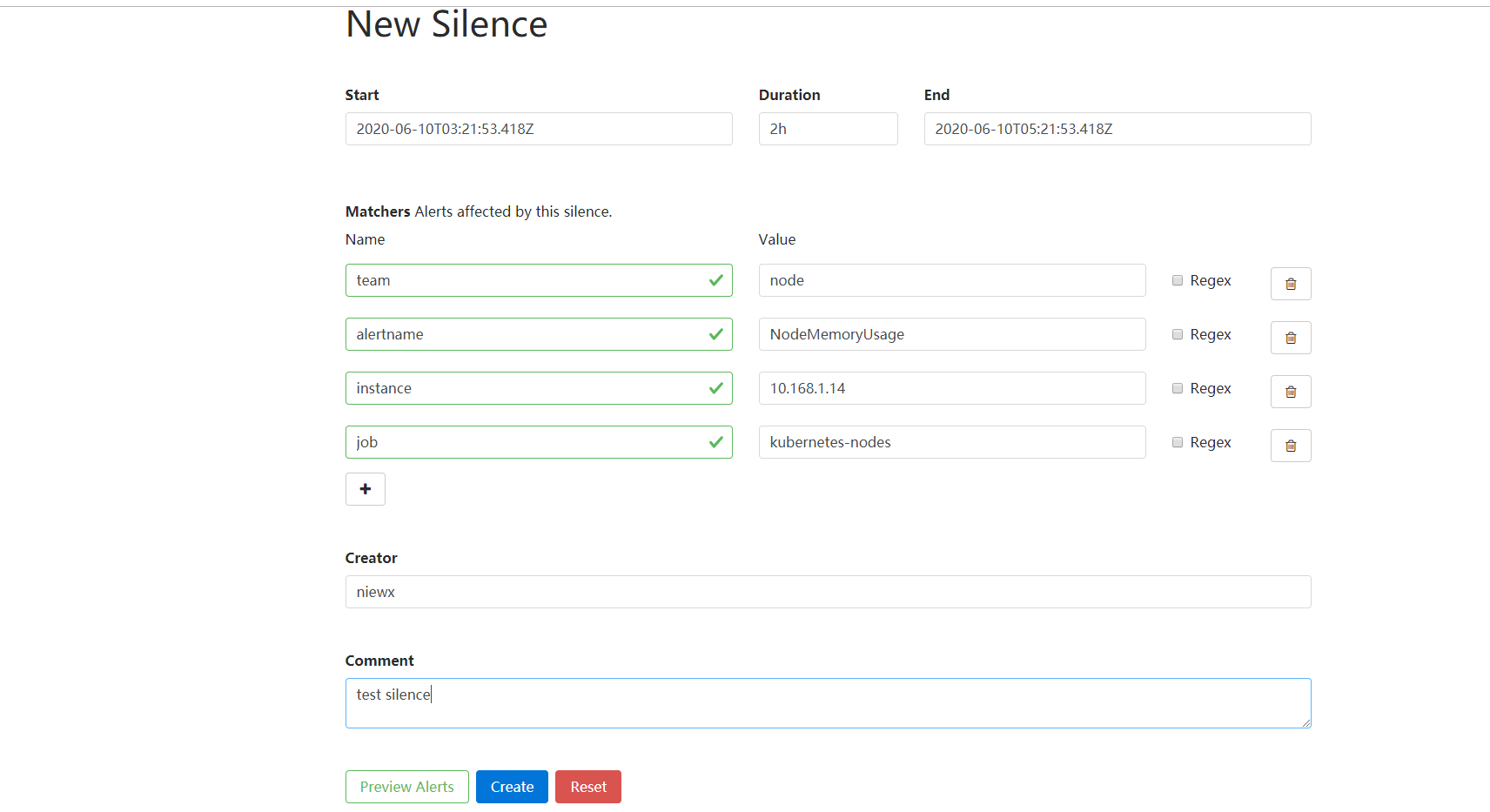
配置ingress通过域名访问
将域名解析到对应的vip上
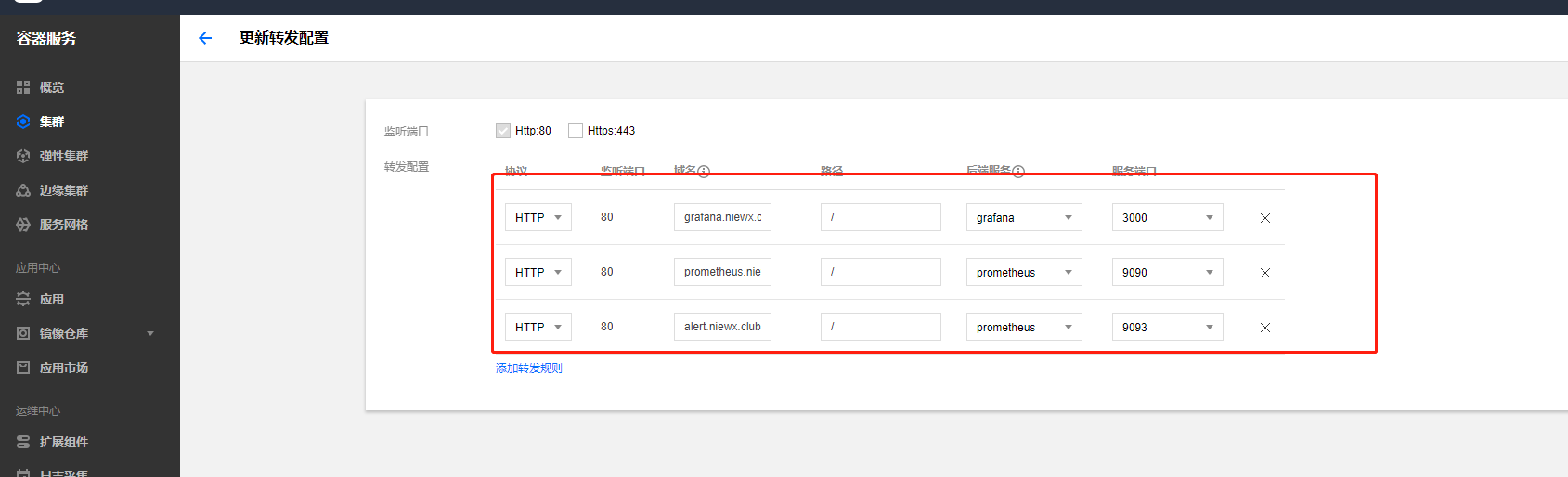
配置好ingress的转发规则
通过域名来访问