使用k8s的时候,会遇到一种情况就是需要单独采集下某个服务的日志进行过滤分析,这时候我们可以单独给服务部署一个filebeat的sidecar来采集过滤日志,下面我们来讲下如何部署
这里我们举例收集nginx服务的容器日志,直接部署下面的yaml文件即可
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: log
spec:
replicas: 2
selector:
matchLabels:
project: www
app: nginx
template:
metadata:
labels:
project: www
app: nginx
spec:
imagePullSecrets:
- name: qcloudregistrykey
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
name: web
protocol: TCP
resources:
requests:
cpu: 0.5
memory: 256Mi
limits:
cpu: 1
memory: 1Gi
volumeMounts:
- name: nginx-logs
mountPath: /var/log/nginx
- name: filebeat
image: elastic/filebeat:7.3.1
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
resources:
limits:
memory: 500Mi
requests:
cpu: 100m
memory: 100Mi
securityContext:
runAsUser: 0
volumeMounts:
- name: filebeat-config
mountPath: /etc/filebeat.yml
subPath: filebeat.yml
- name: nginx-logs
mountPath: /var/log/nginx
volumes:
- name: nginx-logs
emptyDir: {}
- name: filebeat-config
configMap:
name: filebeat-nginx-config
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-nginx-config
namespace: log
data:
filebeat.yml: |-
filebeat.inputs:
- type: log
paths:
- /var/log/nginx/access.log
# tags: ["access"]
fields:
app: www
type: nginx-access
fields_under_root: true
setup.ilm.enabled: false
setup.template.name: "nginx-access"
setup.template.pattern: "nginx-access-*"
output.elasticsearch:
hosts: ['elasticsearch-master.log:9200']
index: "nginx-access-%{+yyyy.MM.dd}"
这里我们对上面的yaml进行说明下,我们将filebeat和nginx的/var/log/nginx目录挂载到emptyDir下,这样filebeat就可以直接读取到了nginx容器的日志目录,然后配置了一下filebeat的配置项,里面配置了日志采集的路径,以及输出的地址和索引名称,这里是直接收集到es里,当然你也可以投递到logstash和kafka
logstash和kafka的配置参考如下
output.logstash: #logstash输出模块
enabled: true #启用模块
hosts: ["localhost:5044"] #logstash地址
worker: 1 #每个logstash的worker数?????,默认1
compression_level: 3 #压缩级别,默认3
loadbalance: true #负载均衡开关,在不同的logstash间负载
pipelining: 0 #在处理新的批量期间,异步发送至logstash的批量次数?????
index: 'filebeat' #可选配置,索引名称,默认为filebeat
proxy_url: socks5://user:password@socks5-server:2233 #socks5代理服务器地址
proxy_use_local_resolver: false #使用代理时是否使用本地解析,默认false
output.kafka: #kafka输出模块
output.redis: #redis输出模块
enabled: true #启用模块
hosts: ["localhost:6379"] #redis地址,地址为一个列表,如果loadbalance开启,则负载到里表中的服务器,当一个redis服务器不可达,事件将被分发到可到达的redis服务器
port: 6379 #redis端口,如果hosts内未包含端口信息,默认6379
key: filebeat #事件发布到redis的list或channel,默认filebeat
password: #redis密码,默认无
db: 0 #redis的db值,默认0
datatype: list #发布事件使用的redis数据类型,如果为list,使用RPUSH命令(生产消费模式)。如果为channel,使用PUBLISH命令{发布订阅模式}。默认为list
worker: 1 #为每个redis服务器启动的工作进程数,会根据负载均衡配置递增
loadbalance: true #负载均衡,默认开启
timeout: 5s #redis连接超时时间,默认5s
max_retries: 3 #filebeat会忽略此设置,并一直重试到全部发送为止,其他beat设置为0即忽略,默认3次
bulk_max_size: 2048 ##对一个redis请求或管道批量的最大事件数,默认2048
proxy_url: #socks5代理地址,必须使用socks5://
proxy_use_local_resolver: false #使用代理时是否使用本地解析,默认false
因为我的es以及接到kibana里面了,这里我们试试在集群内访问下nginx服务的svc,在kibana是否能检索到日志
[root@VM-0-3-centos block]# for i in {1..100}; do curl http://172.16.90.29/; done
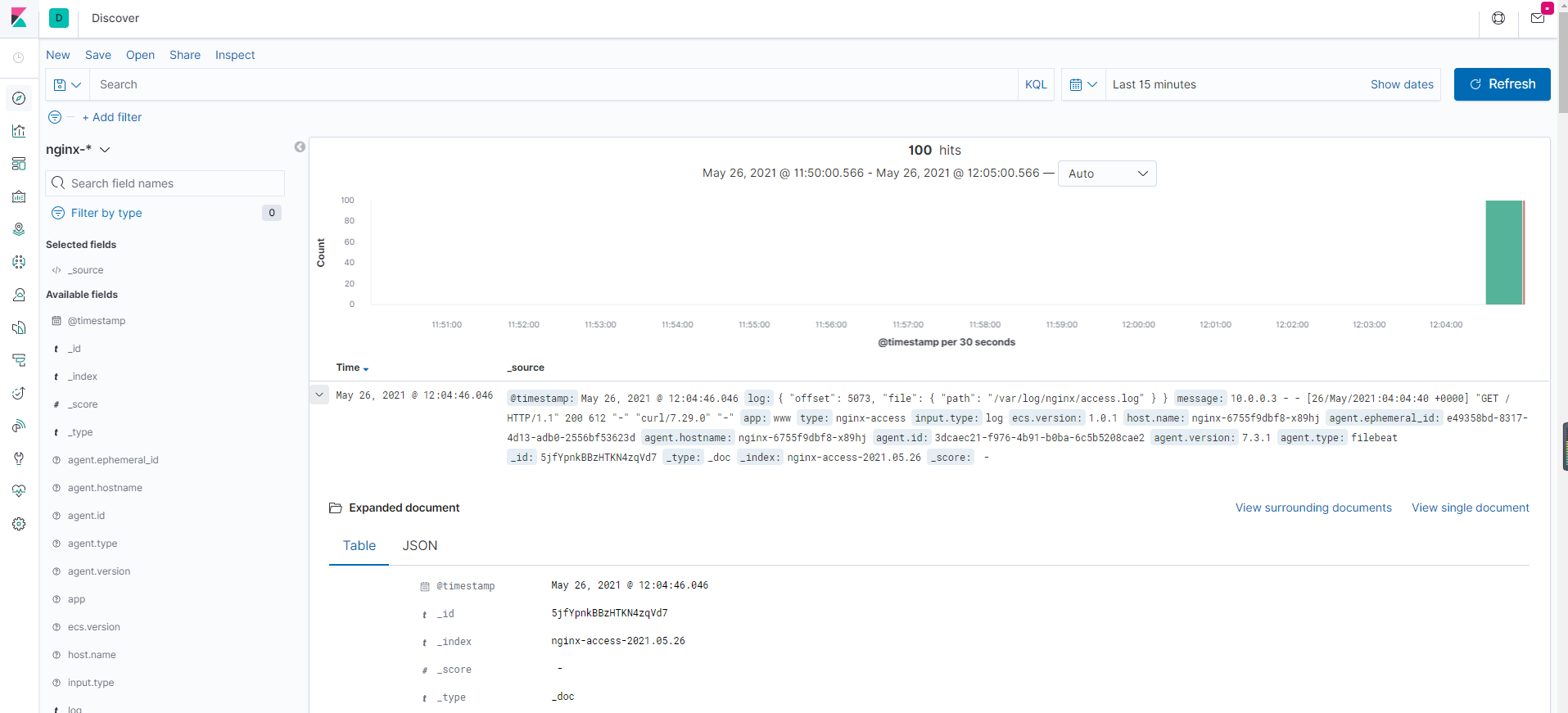
访问后,这里刷新下kibana,可以收到刚访问日志,我们访问了100次,这里也刚好收集100条